Transmit Knowledge, not Behaviors: the Primacy Bias and the Evolutionary Value of Death
14 May 2022
Reinforcement Learning is about maximizing a reward signal from the environment. Since rewards come from the actions of an agent, reinforcement learning is really about learning reward-maximizing behaviors. But an agent seeking effective behaviors should at the same time acquire knowledge about the environment, in a never-ending cycle: a more interesting behavior potentially leads to new knowledge, that in turn unlocks the possibility to refine existing behaviors or learn new ones.
7 Model-based RL Papers I liked from NeurIPS 2020
30 Dec 2020
Here is a bunch of brief informal impressions on the ideas behind some of the reinforcement learning papers I enjoyed at NeurIPS 2020. For the full story, including the experimental or theoretical results, I encourage you to check out the full works, that are linked. The common thread in all of these works? Some form of, explicit or implicit, model-based reinforcement learning.
8 Albums I liked from 2020
30 Dec 2020
2020 was a difficult year for many. In difficult times, music, and art in general, has a very special role for society and individuals. To thank the artists that helped me and thousands of other music lovers go through this year, I want to give my impressions on my favorite eight albums from the last twelve months, restricting myself to three macro-genres that I enjoy, neoclassical, jazz and rock.
How to learn a useful Critic? By model-based RL!
30 Apr 2020
There is a number of potential gains in using an approximate model in reinforcement learning, in terms, for instance, of safety and, as most commonly affirmed, sample-efficiency. However, there is an advantage that should not be forgotten and that is, perhaps, the most interesting: approximating the environment dynamics can unlock peculiar learning modalities that would be impossible in a model-free setting. We will see in this blog post that model-based techniques can be leveraged to obtain a critic that is tailor-made for policy optimization in an actor-critic setting. How? By allowing the critic to explicitly learn to produce accurate policy gradients.
Model-based Policy Gradients
26 Jan 2020
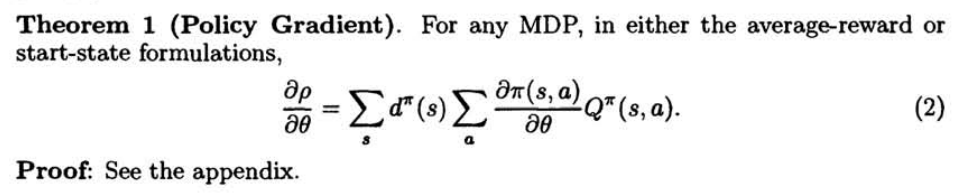 You recognized it. This is the super-handy expression for the policy gradient derived more than 20 years ago by Richard Sutton and colleagues.
In this blog post, I will show how the Policy Gradient Theorem can offer a lens to interpret modern model-based policy search methods. Yes, even the ones that do not directly consider it.
You recognized it. This is the super-handy expression for the policy gradient derived more than 20 years ago by Richard Sutton and colleagues.
In this blog post, I will show how the Policy Gradient Theorem can offer a lens to interpret modern model-based policy search methods. Yes, even the ones that do not directly consider it.